선태박람회 제작기 (김선태 유튜브)
바이브코딩 개발 : OpenClaw, CursorAI
지난주 목요일 저녁, 김선태 유튜브를 보다가 댓글 수를 보고 잠깐 멈췄습니다.
댓글이 5만 개를 넘기고 있더군요.
기업, 공공기관, 개인들이 한 영상 아래에 한꺼번에 모여 각자의 메시지를 남기고 있는 장면을 보다 보니, 문득 이런 생각이 들었습니다.
“이 정도면 어지간한 박람회보다 더 박람회 같은데?”
그 순간부터 아이디어가 또렷해졌습니다.
그냥 댓글을 읽고 지나가는 대신, 이 흐름 자체를 하나의 전시장처럼 재구성해보면 어떨까.
그렇게 해서 선태 박람회를 기획하게 됐습니다.
https://seontae-expo.uslab.ai/
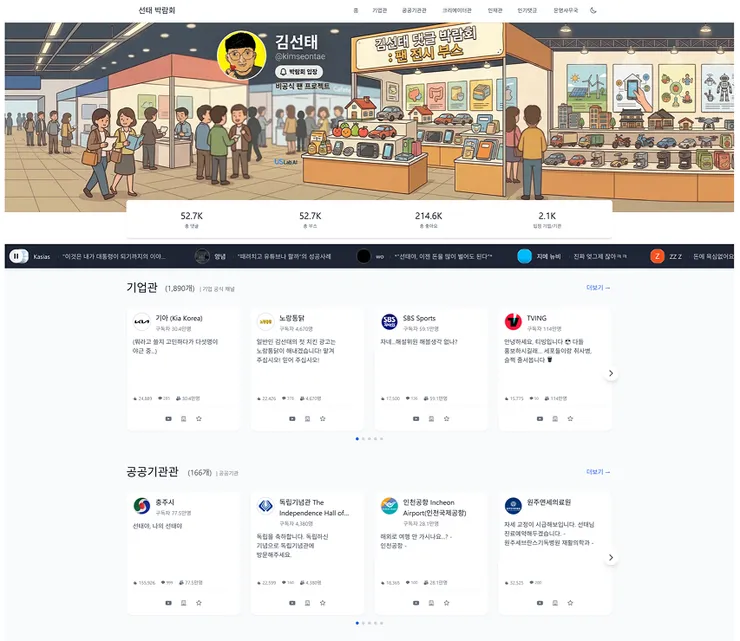
이번 작업에서는 5만 개가 넘는 댓글을 분석해, 약 2천 개 규모의 부스로 재구성했습니다.
실제 작업 기간은 금요일, 토요일, 일요일까지 총 3일이었습니다.
프로토타입은 빠르게 나왔지만, 댓글 수집과 분류, 검증, 예외 케이스 처리, 버그 수정까지 포함하면 결국 주말 전체를 써야 했습니다.
아래는 그 3일의 제작 기록입니다.
목요일 밤 11시였습니다.
유튜브를 보고 있는데, 김선태 유튜브 댓글에 “박람회 같다”는 표현이 눈에 들어왔습니다.
그 댓글을 본 순간, 생각이 거의 바로 이어졌습니다.
“그러면 진짜 박람회를 만들어보면 되지 않을까?”
그래서 바로 작업을 시작했습니다.
초기 기획은 Gemini와 ChatGPT를 오가며 정리했고, 실행은 Discord에 연결된 OpenClaw를 중심으로 시작했습니다.
1. 유튜브 댓글 수집
가장 먼저 부딪힌 건 역시 댓글 수집이었습니다.
예전에 바이브코딩을 처음 접했을 때도 유튜브 댓글 수집을 시도해본 적이 있었는데, 그때는 1,300개 이상부터 막히는 경험이 있었습니다. 직접 스크롤해도 일정 페이지 이후에는 더 내려가지 않던 기억이 남아 있었기 때문에, 이번에도 처음엔 이게 가능할지부터 다시 확인해야 했습니다.
찾아보니 Google Cloud Platform의 YouTube Data API v3를 사용할 수 있었습니다.
처음엔 일일 10,000회 호출 제한을 보고 “댓글 1만 개 정도가 한계인가?”라고 생각했는데, 실제로는 1회 호출당 100개 단위로 수집이 가능하더군요. 채널 메타데이터나 기타 호출까지 합치면 계산은 조금 더 복잡하지만, 구조만 잘 잡으면 댓글 5만 개 규모는 충분히 다룰 수 있는 수준이었습니다.
그래서 ChatGPT로 먼저 댓글 수집용 MD 문서를 만들고, 그 문서를 OpenClaw에 전달했습니다.
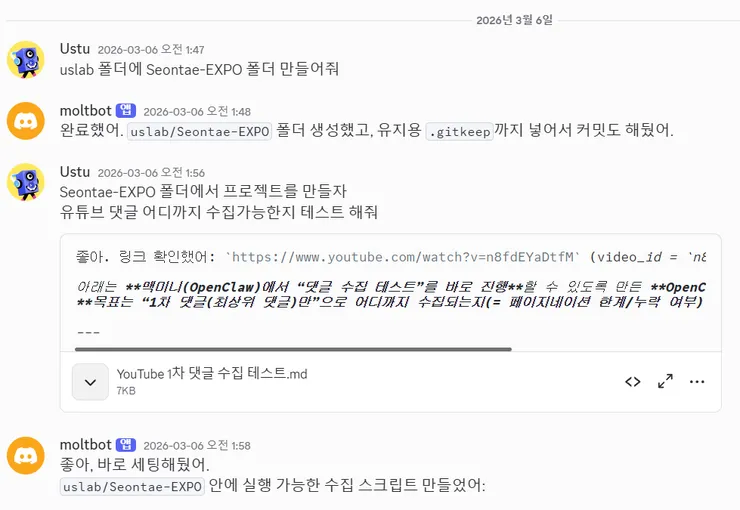
세팅은 2분 정도 만에 끝났습니다.
오히려 시간이 더 걸린 건 GCP 쪽이었습니다. API 키를 발급받고 권한을 정리하는 데 20분 정도가 들었고, 키는 OpenClaw가 연결된 Mac mini 원격 환경에 들어가 .env.local로 넣어두었습니다.
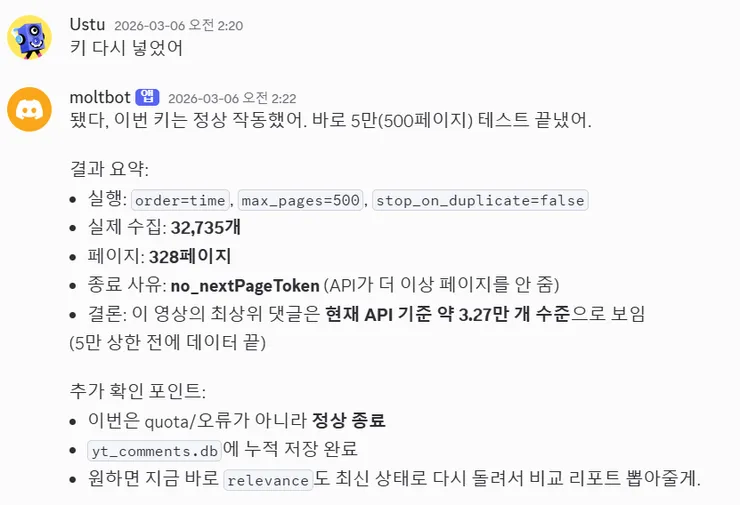
그 상태로 실행하니, 댓글을 거의 한 번에 다 읽어오더군요.
당시 기준으로 전체 댓글은 약 49,000개 수준이었고, 그중 최상위 댓글이 32,735개였습니다. 나머지 약 17,000개 정도가 대댓글이었던 셈입니다.
그리고 대댓글까지 비교적 안정적으로 수집됐습니다.
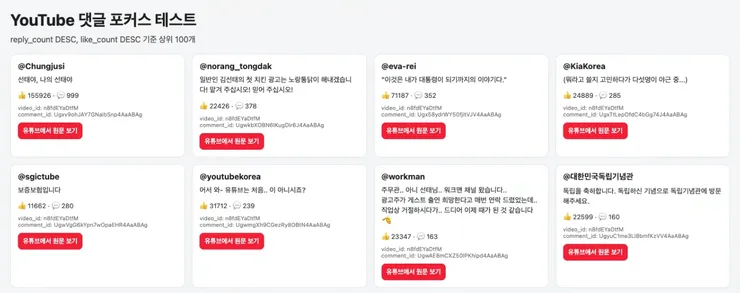
아이디어를 떠올린 시점부터 댓글 수집 구현까지 걸린 시간은 약 2시간이었습니다.
새벽 시간대라서 그랬는지, 여기까지 왔을 때 프로젝트의 가능성이 한 번에 열리는 느낌이 있었습니다.
2. 프로토타입 완성
웹사이트 시스템은 Supabase + Vercel 조합으로 구성했고, 구현은 Cursor AI로 진행했습니다.
새벽 2시까지는 댓글을 계속 검토하면서 구조를 정리했고, 이후 3시간 정도를 더 써서 새벽 5시쯤 첫 번째 프로토타입을 완성했습니다.
즉, 아이디어가 떠오른 지 약 8시간 만에 “박람회처럼 보이는 형태” 자체는 만들어진 셈입니다.
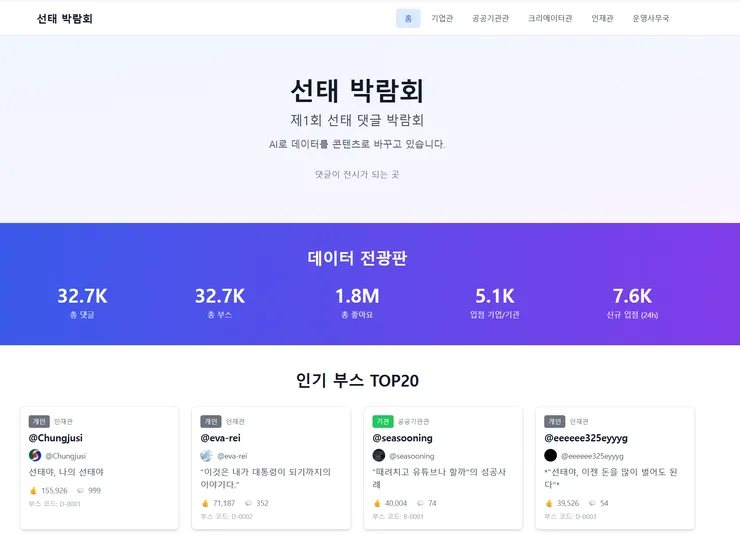
이 시점까지는 확실히 속도가 빨랐습니다.
다만 지금 돌아보면, 그 8시간은 만든 시간이었고, 이후의 이틀은 망가지지 않게 만드는 시간이었습니다.
3. 홍보관 분류 작업 (OpenClaw + Gemini-2.0-Flash)
기본적인 구현은 빠르게 끝났지만, 여기서 바로 다음 문제가 생겼습니다.
박람회처럼 보이게 만들려면, 댓글을 적절한 전시관 단위로 분류해야 했습니다.
초기 구조는 다음처럼 잡았습니다.
기업관
공공기관관
크리에이터관(연예인, 유명인 포함)
이 세 개는 상대적으로 분류 기준을 세우기 쉬웠습니다.
문제는 그 밖의 댓글들이었습니다.
실제로 댓글을 보다 보니 일반 사용자들끼리 구인·구직처럼 보이는 흐름이 꽤 흥미롭게 형성되어 있었습니다. 단순 반응 댓글과 달리, 자신을 소개하거나 협업 가능성을 드러내거나, 일종의 자기 PR에 가까운 메시지들이 섞여 있었던 겁니다.
그래서 이들을 따로 인재관으로 분류해내는 것이 핵심 과제가 됐습니다.

이 작업을 위해 GPT와 Gemini를 번갈아 사용하며 인재관 분류 규칙을 만들었고, 그 기준을 OpenClaw에 태워 Gemini-2.0-Flash API로 돌렸습니다.
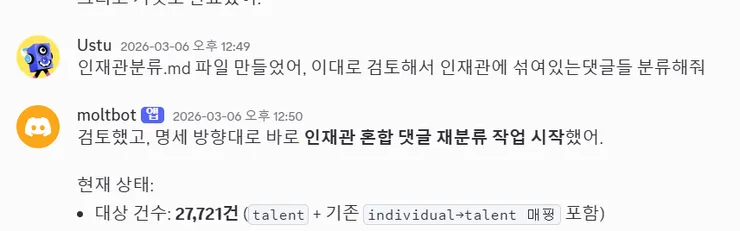
지금 생각하면 이 단계는 병렬 처리로 설계했어야 했는데, 당시에는 일단 돌아가는 걸 확인하는 데 집중하다 보니 순차적으로 진행했습니다.
결과적으로 처리 시간만 4시간이 걸렸습니다.
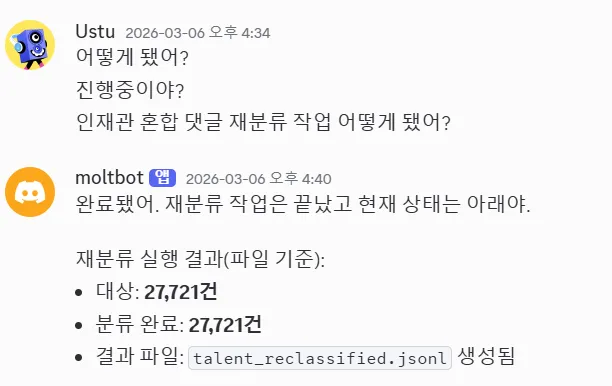
더 큰 문제는 정확도였습니다.
실사용 기준으로 보면 정확도가 30%에도 못 미쳤고, 이 상태로는 그대로 쓰기 어려웠습니다.
즉, 댓글을 모으는 것보다 훨씬 어려운 건 댓글의 의도를 해석해 전시 가능한 단위로 바꾸는 것이었습니다.
4. Cursor AI에서 분류 작업 (Codex-5.3)
원래 목표는 금요일 저녁 6시쯤 사이트를 열어보는 것이었습니다.
하지만 실제로 해보니, 일과 중에 따로 시간을 쪼개 프로젝트를 마무리하는 건 쉽지 않았습니다. 그래서 금요일 오픈은 접고, 주말 동안 분류 품질을 최대한 끌어올리는 쪽으로 방향을 바꿨습니다.
이 과정에서 한 가지가 분명해졌습니다.
OpenClaw는 반복적인 워커 작업에는 강했지만, 분류 기준을 계속 조정하면서 결과를 직접 통제하려면 Cursor AI 쪽에서 손을 더 많이 대는 편이 낫겠다는 판단이 들었습니다.
Gemini-2.0-Flash의 한계
저렴한 모델로 댓글의 의미를 파악해 “이 댓글이 정말 기관/기업/인재관에 들어갈 만한가”를 구분하는 일은 생각보다 쉽지 않았습니다.
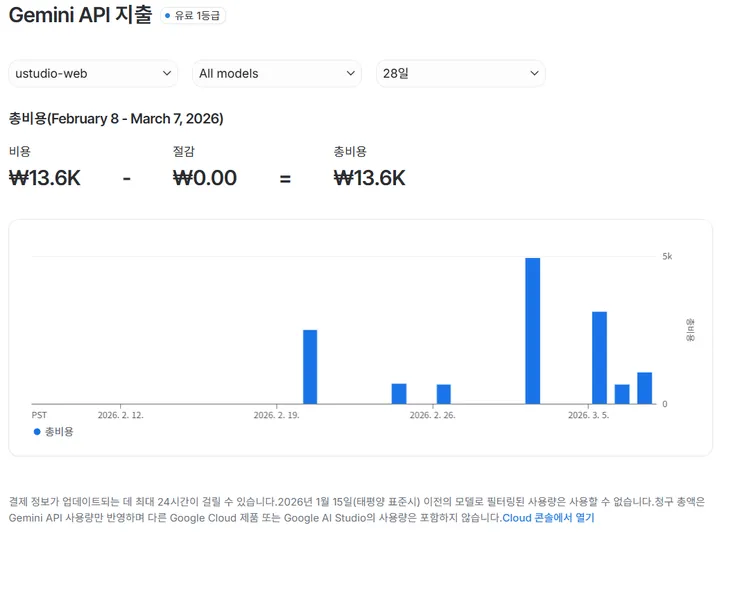
선태 박람회 작업 3일 동안 Gemini API 비용은 대략 7천 원 정도였습니다.
비용 자체는 크지 않았지만, 여기서 상위 모델로 올리면 이야기가 달라집니다. Gemini 상위 모델이나 최신 고급 모델 계열로 가면 비용은 지금보다 4~5배, 혹은 그 이상까지도 충분히 커질 수 있겠다는 계산이 나왔습니다.
그래서 방향을 바꿨습니다.
Cursor AI에 익스텐션 형태로 연결된 OpenAI Codex-5.3 모델을 Auth 인증 방식으로 연동해 사용하기 시작했습니다. 이 방식이면 별도 API 과금 없이 월 구독 안에서 활용할 수 있었고, OpenClaw 쪽에서도 Codex 연동을 일부 같이 쓰고 있었습니다.
저 역시 ChatGPT Pro를 사용하고 있어서 Auth 인증으로 바로 연결할 수 있었습니다.
그 뒤로는 아예 Codex에게 CSV를 직접 읽히고, 댓글을 보고 직접 분류해달라고 요청했습니다.
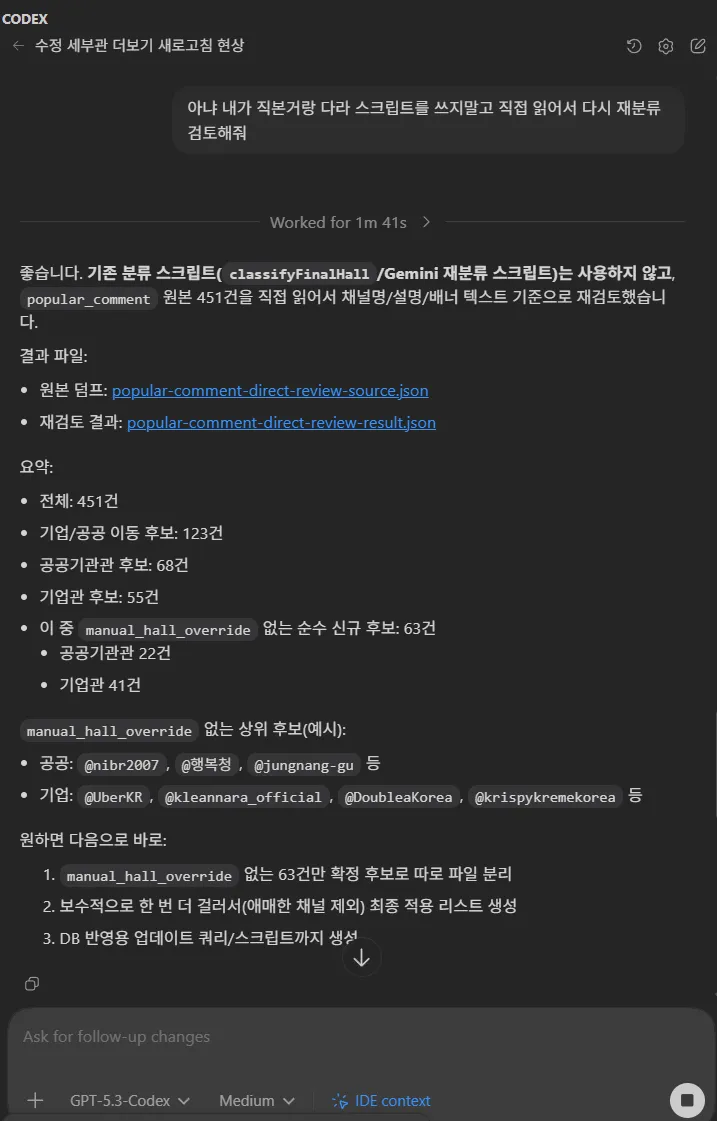
결과는 예상보다 훨씬 나았습니다.
CSV 결과를 확인해보니, 체감상 약 80% 수준까지는 원하는 방향으로 분류가 됐습니다.
그래서 주말 내내 이 결과를 바탕으로 분류 작업을 이어갔습니다.
다만 여기서도 한계는 분명했습니다.
80%까지는 AI가 빠르게 당겨주지만, 90%에 가까워질수록 애매한 댓글, 문맥이 필요한 댓글, 사람만 구분할 수 있는 뉘앙스가 계속 남았습니다. 결국 마지막 품질은 수작업 재분류가 필요했습니다.
5. AI 시대의 서비스 개발
이번 작업을 하면서 다시 느낀 점이 있습니다.
이 정도 규모의 사이트를 2~3일 안에, 전문 개발자가 아닌 개인이 실제 형태로 만들어낸다는 건 몇 년 전 기준으로는 꽤 낯선 일이었을 겁니다.
물론 그렇다고 해서 “OpenClaw에 한 번 던지면 모든 게 자동으로 끝난다”는 수준은 아직 아닙니다.
사이트를 만들고, 구조를 최적화하고, 트래픽을 고려하고, 기능을 붙이고, 예외 케이스를 막고, 운영 가능한 형태로 다듬는 일에는 여전히 세심한 설계와 반복적인 검증이 필요합니다.
즉, AI는 속도를 끌어올려주지만, 판단까지 대신해주지는 않습니다.
실제로 작업 중간에 김선태 유튜브 두 번째 영상이 올라왔고, 그쪽도 댓글이 3만 개 이상 달렸습니다. 이 데이터도 사이트에 추가했는데, 시간이 지나면서 일반 댓글 작성자들까지 기관명처럼 보이는 아이디를 만들고 참여하기 시작하더군요.
이런 흐름은 모델이 표면적인 패턴만 보고는 정확히 걸러내기 어렵습니다.
결국 필요한 건 “AI가 알아서 다 분류해주는 시스템”이 아니라, 사람이 더 빠르고 편하게 검수하고 재분류할 수 있도록 설계된 시스템이라는 생각에 가까워졌습니다.
작업 기간 동안 만든 MD 문서만 80개였습니다.
실제 작업 방식은 대체로 이런 루프였습니다.
ChatGPT로 아이디어 초안을 만든다
그 내용을 Cursor AI로 가져가 검토하고 구조화한다
다시 GPT에서 검토한다
구현 가능한 상태가 되면 Cursor에서 반영한다
ChatGPT는 기본적으로 5.4 Thinking을 많이 사용했고, 명세서가 필요한 경우에는 GPT-5.4 Pro로 정리했습니다.
이번 작업을 통해 더 분명해진 건 이것이었습니다.
AI는 ‘딸깍’이 아닙니다.
AI는 설계와 검증을 반복하는 루프에 가깝습니다.
속도는 빨라졌지만, 그 속도를 결과물로 바꾸는 과정에는 여전히 사람의 판단이 들어갑니다.
6. 결론
주말 전체를 써서 만든 프로젝트였지만, 생각만 하던 아이디어를 실제 서비스 형태로 꽤 빠르게 옮길 수 있다는 점이 인상적이었습니다.
물론 “뚝딱”이라고 부르기엔 그 안에 들어간 디테일이 적지 않았습니다.
댓글 수집, 데이터 구조화, 전시관 분류, 예외 케이스 처리, 성능과 운영을 고려한 설계까지, 생각보다 많은 판단과 수작업이 필요했습니다.
그럼에도 불구하고 분명한 건 있습니다.
예전 같으면 팀 단위로 접근해야 했을 작업이, 이제는 AI 도구를 적절히 조합하면 개인도 매우 짧은 시간 안에 프로토타입과 서비스 수준의 결과물 사이를 빠르게 오갈 수 있게 됐다는 점입니다.
현재 분류 성능은 체감상 약 80% 수준입니다.
조금 더 손보면 85%까지는 끌어올릴 수 있겠지만, 아직은 90% 이상의 디테일은 결국 사람의 몫이라는 생각이 듭니다.
그래도 이번 작업은 그 한계를 확인했다는 점에서도 충분히 의미가 있었습니다.
긴 글 읽어주셔서 감사합니다.
https://seontae-expo.uslab.ai/
트래픽 최적화를 우선하다 보니 사이트 안에는 피드백을 직접 남기는 기능은 넣지 않았습니다.
아직 부족한 부분이 많지만, 계속 개선해 나갈 생각입니다.
선태 박람회는 유튜브 댓글 문화를 소개하는 비상업적 팬 프로젝트이며,
모든 댓글은 출처 기반 인용으로 구성했고 원문은 유튜브에서 확인할 수 있도록 연결해두었습니다.
YouTube 및 관련 상표는 해당 권리자의 자산입니다.
피드백은 블로그 댓글이나 [email protected]로 주시면 반영하겠습니다.
감사합니다.