The Making of Seon-tae Expo (Kim Seon-tae's YouTube Channel)
VibeCoding Development: OpenClaw, CursorAI
Last Thursday evening, while watching Kim Seontae's YouTube channel, I paused for a moment to look at the number of comments.
The comments were exceeding 50,000.
Seeing companies, public institutions, and individuals all gathered under one video, leaving their respective messages, I suddenly had this thought:
"At this point, it's more like an expo than an actual expo, isn't it?"
From that moment on, the idea became clear.
Instead of just reading and passing by the comments, what if we restructured this flow itself like an exhibition?
And that's howSeontae Expowas planned.
https://seontae-expo.uslab.ai/
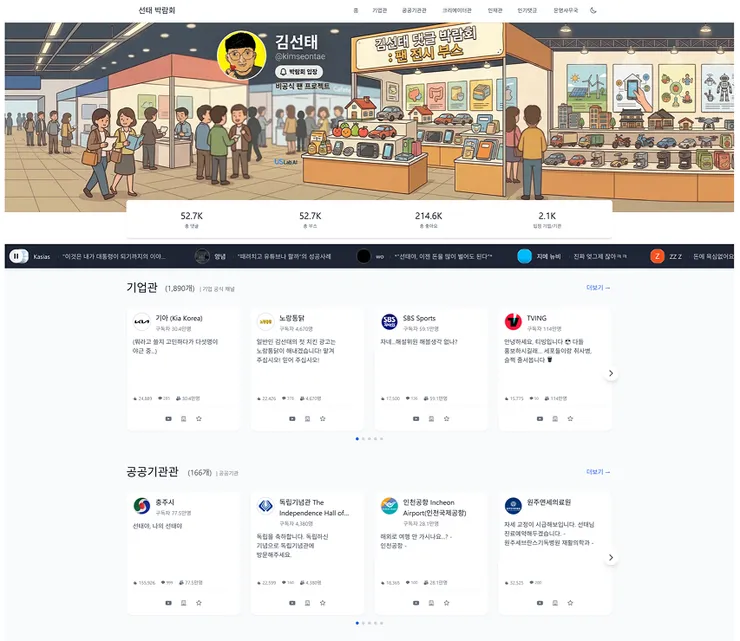
In this project, I analyzed over 50,000 comments and reconstructed them into approximately 2,000 booths.
The actual work period was a total of 3 days, from Friday to Sunday.
The prototype came out quickly, but including comment collection, classification, verification, handling of exceptions, and bug fixes, I ended up spending the entire weekend.
Below is the production log of those 3 days.
It was 11 PM on Thursday night.
I was watching YouTube, and the expression "it's like an expo" in the comments of Kim Seontae's YouTube channel caught my eye.
The thought process followed almost immediately after seeing that comment.
"Then, why not create a real expo?"
So, I started working right away.
The initial planning was done by going back and forth between Gemini and ChatGPT, and the execution began with OpenClaw connected to Discord.
1. YouTube Comment Collection
The first challenge I faced was, of course, collecting comments.
I had tried collecting YouTube comments when I first encountered VibeCoding, but I experienced it being blocked after 1,300 comments. I remembered that even when scrolling manually, it wouldn't go down further after a certain page, so I had to reconfirm whether this was even possible this time.
I found that I could use Google Cloud Platform'sYouTube Data API v3.
At first, I thought, "Is the limit about 10,000 comments?" after seeing the daily limit of 10,000 calls, but in reality, it was possible to collect in units of 100 per call. If you add channel metadata or other calls, the calculation becomes a bit more complex, but if you set up the structure well, you can handle a scale of 50,000 comments sufficiently.
So, I first created an MD document for collecting comments with ChatGPT and passed that document to OpenClaw.
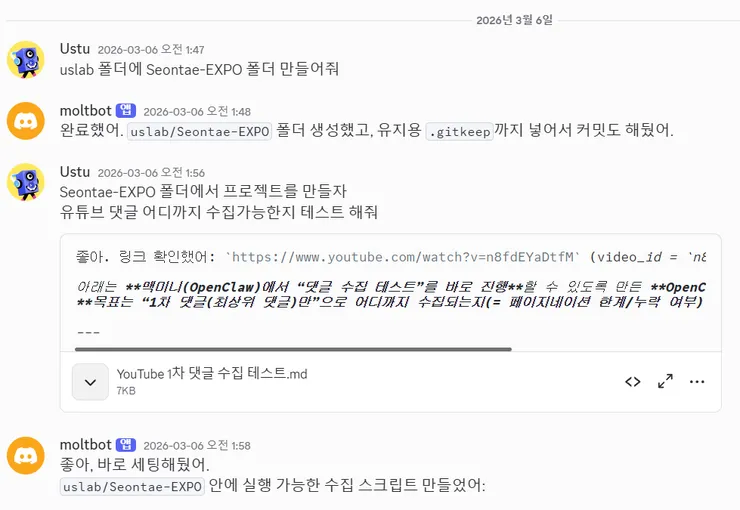
The setup was finished in about 2 minutes.
Rather, it took more time on the GCP side. It took about 20 minutes to issue the API key and organize the permissions, and the key was placed in the Mac mini remote environment connected to OpenClaw.env.local .
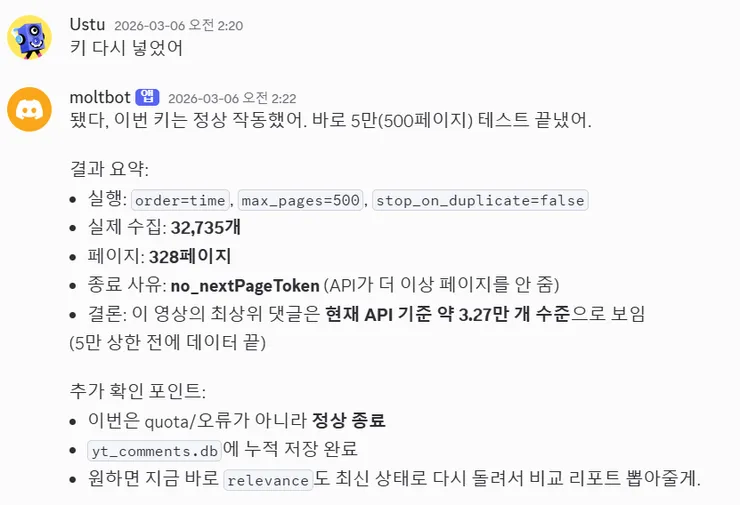
When I ran it in that state, it read almost all the comments at once.
Based on the current data, the total number of comments was about 49,000, of which 32,735 were top-level comments. The remaining approximately 17,000 were replies.
And the replies were collected relatively stably.
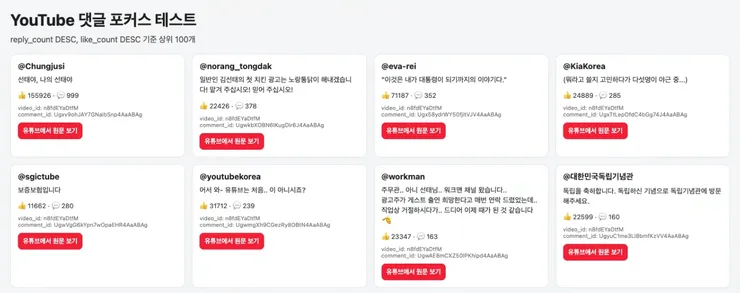
The time from conceiving the idea to implementing comment collection was about 2 hours.
Perhaps it was because it was early morning, but when I got this far, I felt that the potential of the project was unlocked at once.
2. Prototype Completion
The website system wasSupabase + Vercelcombination, and the implementation was done withCursor AI.
I continued to review the comments and organize the structure until 2 AM, and then spent about 3 more hours to complete the first prototype around 5 AM.
In other words, the "form that looks like an expo" itself was created in about 8 hours after the idea came to mind.
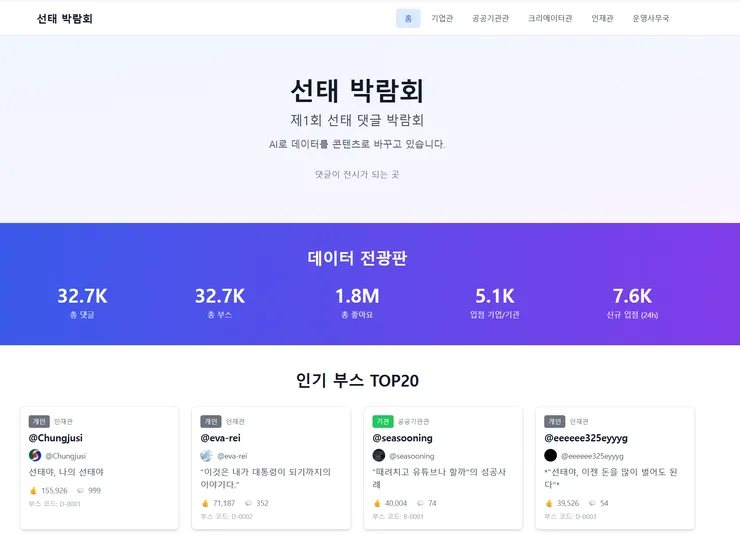
The speed was definitely fast up to this point.
However, looking back now, those 8 hours weretime spent creating,and the following two days weretime spent preventing it from breaking.
3. Pavilion Classification (OpenClaw + Gemini-2.0-Flash)
The basic implementation was completed quickly, but the next problem arose immediately.
To make it look like an expo, the comments had to be classified into appropriate exhibition hall units.
The initial structure was set up as follows:
Corporate Pavilion
Public Institution Pavilion
Creator Pavilion (including celebrities and famous people)
It was relatively easy to establish classification criteria for these three.
The problem was the other comments.
When I actually looked at the comments, I found that a flow that looked like job postings and job seeking among general users was quite interestingly formed. Unlike simple reaction comments, there were messages that introduced themselves, revealed the possibility of collaboration, or were close to a kind of self-promotion.
So, classifying them separately asTalent Pavilionbecame the core task.

For this task, I used GPT and Gemini alternately to create Talent Pavilion classification rules, and ran them on theGemini-2.0-Flash APIthrough OpenClaw.
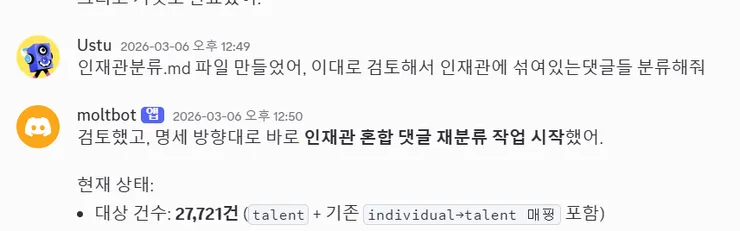
Thinking about it now, this step should have been designed for parallel processing, but at the time, I focused on verifying that it was working, so I proceeded sequentially.
As a result, the processing time alone took 4 hours.
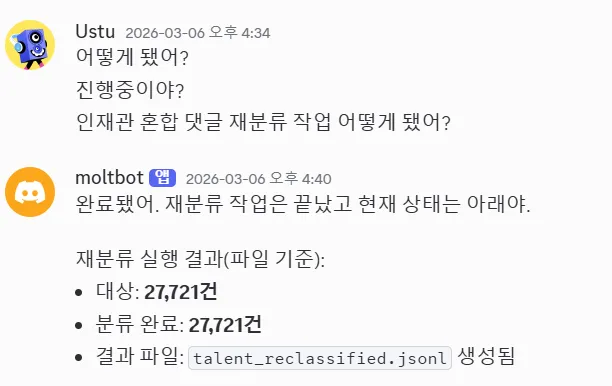
The bigger problem was accuracy.
Based on actual usage, the accuracy was less than 30%, and it was difficult to use it as is in this state.
In other words,collecting commentswas much more difficult thaninterpreting the intent of the comments and converting them into exhibitable units.
4. Classification Work in Cursor AI (Codex-5.3)
The original goal was to open the site around 6 PM on Friday evening.
But in reality, it wasn't easy to spare time during work to finish the project. So, I gave up on opening on Friday and changed the direction to maximizing the classification quality during the weekend.
One thing became clear in this process.
OpenClaw was strong for repetitive worker tasks, but I decided that it would be better to work more on the Cursor AI side to continuously adjust the classification criteria and directly control the results.
Limitations of Gemini-2.0-Flash
It was more difficult than expected to understand the meaning of comments with a cheap model and distinguish "Is this comment really worth going into the institution/company/talent hall?"
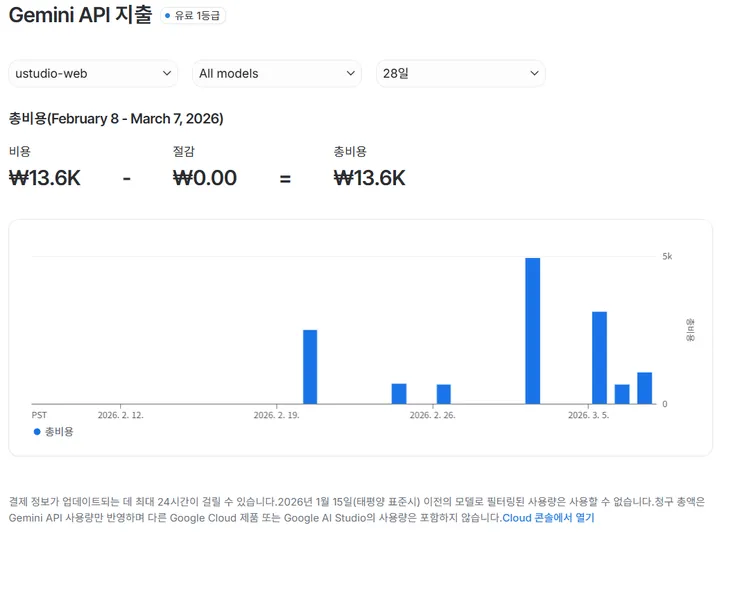
The Gemini API cost for the Seontae Expo project was approximately 7,000 KRW for 3 days.
The cost itself was not significant, but the story changes if you move to a higher model here. If you go to a higher Gemini model or the latest high-end model series, the cost could easily increase by 4 to 5 times or more.
So, I changed the direction.
TheOpenAI Codex-5.3 modelconnected to Cursor AI in the form of an extension was linked and used with Auth authentication. With this method, it could be used within the monthly subscription without separate API charges, and OpenClaw was also using some Codex integration together.
I was also using ChatGPT Pro, so I could connect directly with Auth authentication.
After that, I had Codex directly read the CSV and asked it to classify the comments directly.
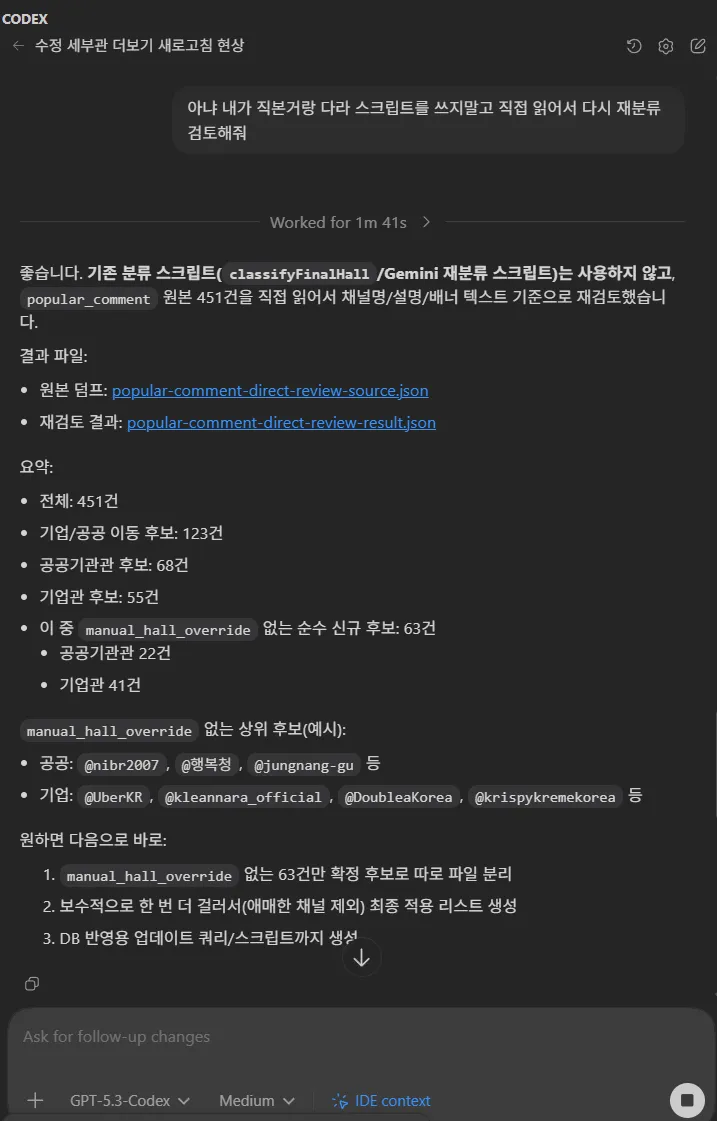
The results were much better than expected.
When I checked the CSV results, I felt thatclassification was done in the desired direction up to about 80%.
So, I continued the classification work based on these results throughout the weekend.
However, the limitations were clear here as well.
AI quickly pulls up to 80%, but as it gets closer to 90%, ambiguous comments, comments that require context, and nuances that only humans can distinguish continue to remain. In the end, the final quality required manual reclassification.
5. Service Development in the Age of AI
I felt again while working on this project.
Creating a site of this size in 2-3 days, in actual form, by an individual who is not a professional developer would have been quite unfamiliar a few years ago.
Of course, that doesn't mean that "everything ends automatically once you throw it into OpenClaw" yet.
Building a site, optimizing the structure, considering traffic, adding features, preventing exceptions, and refining it into an operable form still require careful design and iterative verification.
In other words,AI speeds up the process, but it doesn't replace judgment.
In fact, a second video from Kim Seontae's YouTube channel was uploaded in the middle of the project, and more than 30,000 comments were added to that as well. I added this data to the site, but over time, even general commenters started creating IDs that looked like institutional names and participating.
It is difficult for the model to accurately filter out these flows by looking only at superficial patterns.
In the end, what is needed is not "a system where AI automatically classifies everything," buta system designed to allow people to review and reclassify more quickly and easily.That's the thought I've come to.
I created 80 MD documents during the work period.
The actual working method was generally this loop:
Create a draft idea with ChatGPT
Take the content to Cursor AI to review and structure it
Review again in GPT
Reflect in Cursor when it becomes implementable
ChatGPT basically used 5.4 Thinking a lot, and GPT-5.4 Pro was used to organize when specifications were needed.
What became clearer through this work was this:
AI is not a 'click'.
AI is closer to a loop that repeats design and verification.
The speed has increased, but the process of converting that speed into results still involves human judgment.
6. Conclusion
It was a project made using the entire weekend, but it was impressive that I could move the ideas I had only thought about into an actual service form quite quickly.
Of course, there were quite a few details involved to call it "뚝딱".
From comment collection, data structuring, exhibition hall classification, exception handling, and design considering performance and operation, a lot of judgment and manual work was required than I thought.
Nevertheless, one thing is clear.
Tasks that would have required a team approach in the past can now be quickly moved back and forth between prototypes and service-level results by individuals in a very short time by appropriately combining AI tools.
The current classification performance is about 80% in my experience.
I can pull it up to 85% with a little more work, but I still think that details above 90% are ultimately up to humans.
Still, this work was meaningful enough in that it confirmed the limitations.
Thank you for reading the long post.
https://seontae-expo.uslab.ai/
Prioritizing traffic optimization, I didn't include a function to leave feedback directly on the site.
There are still many shortcomings, but I plan to continue to improve it.
Seontae Expo is a non-commercial fan project introducing YouTube comment culture,non-commercial fan projectand
all comments are composed of source-based citations, and the original text is linked so that it can be viewed on YouTube.
YouTube and related trademarks are the property of their respective owners.
Feedback can be given in the blog comments or[email protected]and we will reflect it.
Thank you.